Particle images Classification using arrays and xgboost
Karim Mezhoud
2020-02-19
0.1 set python version and anaconda environment
1 Particle type classification
Welcome!
In this challenge we want to build a machine learning model to help us recognize particles. Particles are the tiny constituant of matter generated in a collision between proton bunches at the Large Hadron Collider at CERN.
Particles are of course of different types and identifying which particle was produced in an extremly important task for particle physicists.
Our dataset comprises 350 independent simulated events, where each event contains labelled images of particle trajectories.
A good model assigns the correct particle type to any particle, even the least frequent ones.
Read throught this notebook to discover more about the particles.
#Import libraries to load and process data
import numpy as np
import pandas as pd
import pickle
import os
from collections import Counter
from numpy import unique# replace by your own file path
pkl_file = open("download/event1.pkl", 'rb')
event1 = pickle.load(pkl_file)
np.shape(event1)
def get_pkl_filename(path):
list_files = os.listdir(path)
PIK = "pickle.dat"
with open(PIK, "wb") as f:
pickle.dump(len(list_files), f)
for value in list_files:
pickle.dump(value, f)
filename_ls = []
with open(PIK, "rb") as f:
for _ in range(pickle.load(f)):
filename_ls.append(pickle.load(f))
return(filename_ls)
list_file = get_pkl_filename("download/")
# Glimpse the format of the output
isinstance(list_file, list)path = 'download/'
#pkl = [pickle.load(path + s) for s in list_file]
def load_pkl(file_pkl):
with open(file_pkl, 'rb') as pickle_file:
content = pickle.load(pickle_file)
return(content)
pkl = [load_pkl(path + '/' + s) for s in list_file]
len(pkl)from sklearn.preprocessing import LabelEncoder
arrays = [item[0] for item in pkl]
labels = [item[1] for item in pkl]
# convert a list of narray to narray
xtrain = np.stack(np.concatenate( arrays, axis=0 ), axis=0)
# reshape array from (1176475,10,10) to 2 dimension (1176475, 100)
xtrain = xtrain.reshape(len(xtrain),-1)
# Convert a list of narray to array
ytrain = np.stack(np.concatenate( labels, axis=0 ), axis=0)
# Encode labels
ytrain_en = LabelEncoder().fit(ytrain).transform(ytrain)
#ytrain_en = pd.DataFrame(ytrain_en)
type(xtrain)
train = pd.DataFrame({'label': ytrain_en, 'images': list(xtrain)}, columns=['label', 'images'])
xtrain.shape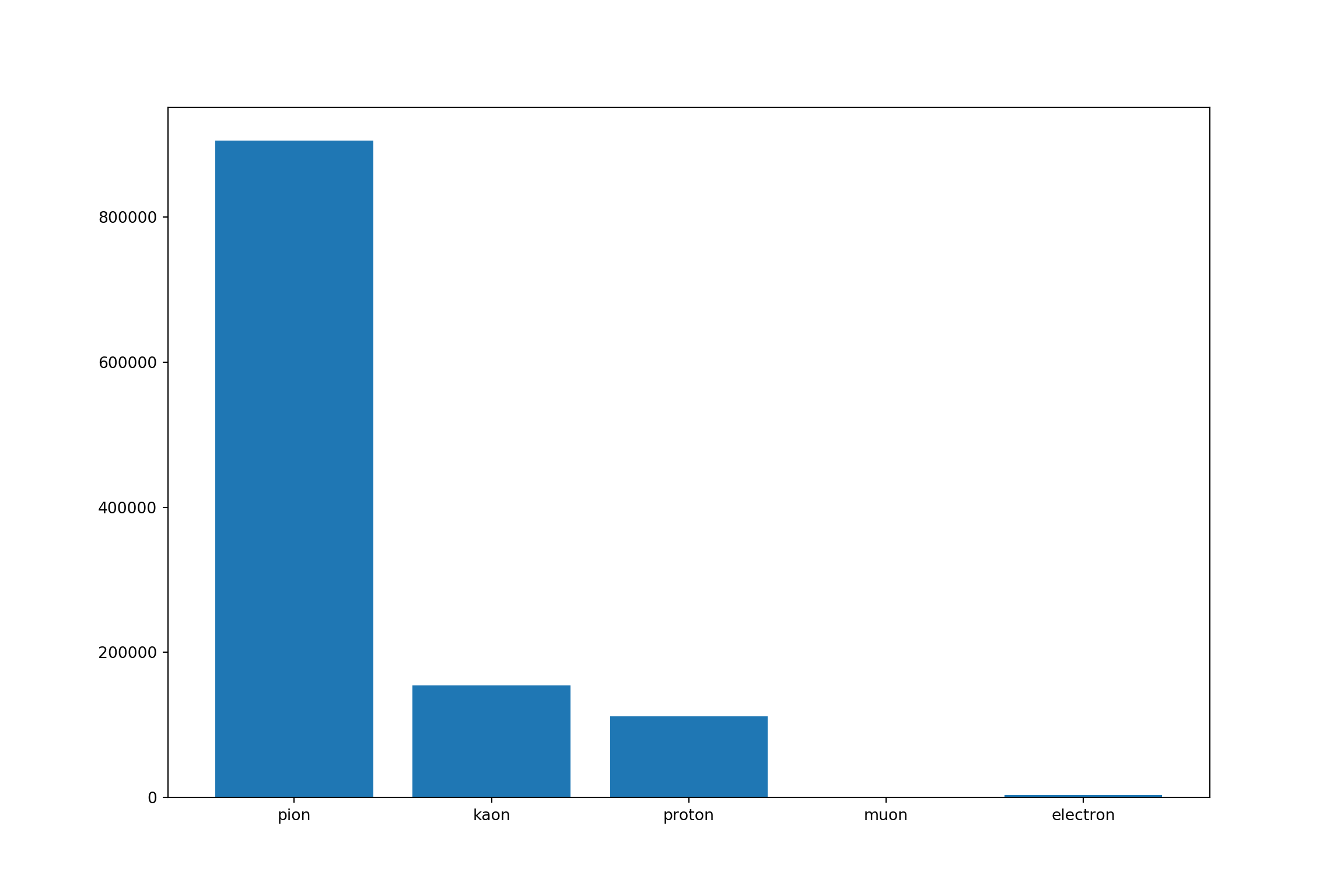
2 Up-sample Minority Classes
# Separate minors and major classes
train_0 = train[train.label == 0]
train_1 = train[train.label == 1]
train_2 = train[train.label == 2]
train_3 = train[train.label == 3]
train_4 = train[train.label == 4]from sklearn.utils import resample
# Upsample minority classes
train_0_upsampled = resample(train_0,
replace=True, # sample with replacement
n_samples=111730, # to match majority class
random_state=123) # reproducible results
# Upsample minority classes
train_1_upsampled = resample(train_1,
replace=True, # sample with replacement
n_samples=111730, # to match majority class
random_state=123) # reproducible results
# Downsample majority class
train_2_downsampled = resample(train_2,
replace=False, # sample without replacement
n_samples=111730, # to match minority class
random_state=123) # reproducible results
# Downsample majority class
train_3_downsampled = resample(train_3,
replace=False, # sample without replacement
n_samples=111730, # to match minority class
random_state=123) #
# Combine minority class with downsampled majority class
train_balanced = pd.concat([train_0_upsampled, train_1_upsampled, train_2_downsampled, train_3_downsampled, train_4])
train_balanced.head# plt.bar(range(len(dic_types)),list(Counter(train_balanced['label']).values()))
# plt.xticks(range(len(dic_types)), [dic_types[i] for i in list(Counter(train_balanced['label']).keys())])
#
# plt.show()from numpy import save
# Separate input features (X) and target variable (y)
Y = train_balanced.label
#X = train_balanced.drop('label', axis=1)
X = np.stack(train_balanced.images.values)
save('X.npy', X)
save('Y.npy', Y)
# load array
#Y = load('Y.npy')#import mxnet as mx
from sklearn.model_selection import train_test_split
import xgboost as xgb
import time
## Split
trn_x, val_x, trn_y, val_y = train_test_split(X, Y, random_state = 42,
stratify = Y, test_size = 0.20)
start_time = time.process_time()
clf = xgb.XGBRegressor(booster = 'gbtree',
objective = 'multi:softprob', # multi:softmax, multi:softprob #'reg:squarederror', # reg:linear reg:logistic
num_class = 5,
max_depth = 10,
n_estimators = 100,
min_child_weight = 9,
learning_rate = 0.01,
nthread = 8,
subsample = 0.80,
colsample_bytree = 0.80,
seed = 4242)
clf.fit(trn_x,
trn_y,
eval_set = [(val_x, val_y)],
verbose = True,
#verbose_eval= 10, # print every 10 boost
eval_metric = 'mlogloss', # rmse, logloss, mae, map, cox-nloglik
early_stopping_rounds = 10)
#clf.score(val_x,val_y)
# Predict
preds = clf.predict(val_x)
## Wich max prob
import numpy as np
best_preds = np.asarray([np.argmax(line) for line in preds])
# Determine the precision of this prediction:
from sklearn.metrics import precision_score
precision_score(val_y, best_preds, average='macro')
pkl_test = open("data_test_file.pkl", 'rb')
test = pickle.load(pkl_test)
t1 = np.stack( test, axis=0 )
t2 = np.stack(t1[:,1])
xtest = t2.reshape(len(t2),-1)
X.shapepred_test = clf.predict(xtest)
#pred_test
#np.asarray([np.argmax(line) for line in pred_test])
#dic_types={0: "electron", 1 : "muon", 2:"pion", 3:"kaon",4 : "proton"}
submission = pd.DataFrame(pred_test)
#submission['image'] = submission.index
submission = submission.reset_index()
submission.columns = ['image', 'electron', 'muon', 'pion', 'kaon', 'proton']
#submission.rename( columns={'index': 'image'}, index ={'index', 'image'},axis=, inplace=True)
submission.to_csv("submission.csv")
submission.head